"DFLib" (short for "DataFrame Library") is a lightweight, pure Java implementation of DataFrame. DataFrame is a
very common structure in data science and Big Data worlds. It provides operations like search,
filtering, joins, aggregations, statistical functions, etc., that are reminiscent of SQL (also of Excel), except you run
them in your app over dynamic in-memory data sets.
There are DataFrame implementations in Python (pandas), R,
Apache Spark, etc.
DFLib project’s goal is to provide the same functionality for regular Java applications. It is a simple library, that
requires no special infrastructure. DFLib core is dependency-free.
The code in this documentation can be run in any Java IDE, as well as (and this is pretty cool!) in a Jupyter notebook. You will need Java 11 or newer.
Get Started with DFLib
Include DFLib in a project. Assuming you are using Maven, start by declaring a "BOM" to have a common version for multiple DFLib modules:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-bom</artifactId>
<version>1.2.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Next include DFLib core as a dependency:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib</artifactId>
</dependency>Create a DataFrame, do some manipulations with it, print the result:
DataFrame df1 = DataFrame
.foldByRow("a", "b", "c")
.ofStream(IntStream.range(1, 10000));
DataFrame df2 = df1.rows(r -> r.getInt(0) % 2 == 0).select();
System.out.println(Printers.tabular.toString(df2));When you run this code, console output will look like this:
a b c ---- ---- ---- 4 5 6 10 11 12 16 17 18 ... 9982 9983 9984 9988 9989 9990 9994 9995 9996 1666 rows x 3 columns
| We’ll omit print statements in all the following examples, and will simply display their output. Details of printing are discussed in the in "Printers" chapter. |
Main Data Structures
The two essential DFLib classes are Series and DataFrame. Series is a 1-dimensional array-like object, and DataFrame
is a 2-dimensional table-like object. Columns in a DataFrame are stored as Series. Additionally, we will discuss
Index object that stores DataFrame column names.
Both DataFrame and Series (and Index) are fully immutable, so all operations on them return a new instance. Behind the scenes the library shares as much data as possible between instances, so copying these objects does not cause significant performance degradation, and in turn makes DFLib fully thread-safe, with multiple concurrent operations possible on the same data structure. Also, immutability means that you can have full snapshots of your data at each step of a transformation, simplifying debugging and auditing of data pipelines.
Series
Series is the simplest of the two data structures. You can think of it as a wrapper around an array of values.
You can use Series to model sequences of data such as timestamps in a time series. Series object is parameterized for
the type of data that it holds. So there can be Series<String> or a Series<LocalDate>, etc. There is also an
important category of "primitive" Series (IntSeries, LongSeries, DoubleSeries, BooleanSeries) that are optimized
for memory use and arithmetic operations. Of course, each primitive Series can also pose as Series of a corresponding
wrapper object type (e.g. IntSeries is also a Series<Integer>).
Series object is an important building block of DataFrame, but it defines a number of useful data
manipulation and transformation operations on its own. Those will be covered in the following chapters. Here we’ll
discuss how to create Series.
Creation of Series from Arrays
Series can be created using static ofXyz(..) methods on the Series interface:
Series<String> s = Series.of("a", "bcd", "ef", "g");a bcd ... g 4 elements
Primitive Series classes have their own factory methods. E.g.:
IntSeries is = Series.ofInt(0, 1, -300, Integer.MAX_VALUE);Creation of Series By Element
If we don’t have a data array or collection to start with and instead somehow produce a sequence of
values of unpredictable length, we can use Series.byElement() API. E.g. the following example reads data from
an InputStream line by line as Strings:
// InputStream inputStream = ...
SeriesAppender<String, String> appender = Series
.byElement(Extractor.<String>$col()) (1)
.appender();
Scanner scanner = new Scanner(inputStream);
while (scanner.hasNext()) {
appender.append(scanner.next()); (2)
}
Series<String> s = appender.toSeries();| 1 | Create Series "appender" that will accumulate values. For primitive Series you would use Extractor.$int(..),
Extractor.$long(..) and so on |
| 2 | Append values as they are read one-by-one |
DataFrame
DataFrame is an in-memory table made of an Index header and a number of named columns. Each column is
a Series, and has an associated name in the Index. DataFrame can contain columns of different
kinds, so it is not parameterized for any single type.
"Rows" is a purely virtual concept as the data is organized by column, yet there is a number of APIs that appear to operate on rows for user convenience.
There are a few ways to create a DataFrame. Here we’ll show how to convert various in-memory objects to DataFrames (arrays, Streams, Collections, Series).
| More often than not, a DataFrame is not created from an in-memory object, but is rather loaded from (and saved to) an external source, like a database or a CSV file. Those are discussed in separate chapters. |
First example, adding data row by row:
DataFrame df = DataFrame
.byArrayRow("name", "age") (1)
.appender() (2)
.append("Joe", 18) (3)
.append("Andrus", 49)
.append("Joan", 32)
.toDataFrame();| 1 | A special builder is created to append each row as a vararg array |
| 2 | The builder creates an "appender" object. While here we are using the builder with default settings, it has extra methods to configure capacity, data sampling, etc. |
| 3 | Passing individual rows to the appender one-by-one |
The resulting DataFrame looks like this:
name age ------ --- Joe 18 Andrus 49 Joan 32
A more general example - creating a DataFrame from a list of objects by "extracting" column data from object properties:
record Person(String name, int age) {
}
List<Person> people = List.of(
new Person("Joe", 18),
new Person("Andrus", 49),
new Person("Joan", 32));
DataFrame df = DataFrame
.byRow( (1)
Extractor.$col(Person::name),
Extractor.$int(Person::age))
.columnNames("name", "age") (2)
.appender() (3)
.append(people) (4)
.toDataFrame();| 1 | The builder is started with an array of Extractors. Each extractor generates its own column, filling it with a corresponding object property. |
| 2 | Specifying the names of the DataFrame columns. If omitted, column names are assigned automatically |
| 3 | Creating a row-by-row appender |
| 4 | Appending the list. |
The resulting DataFrame looks like this:
name age ------ --- Joe 18 Andrus 49 Joan 32
Another example - a single-dimensional array can be "folded" into a DataFrame row-by-row:
DataFrame df = DataFrame
.foldByRow("name", "age") (1)
.of("Joe", 18, "Andrus", 49, "Joan", 32); (2)| 1 | Folding Builder is created |
| 2 | Passing a varargs array of values, that is folded to match the specified number of columns, row by row. |
Same, but folding column-by-column:
DataFrame df = DataFrame
.foldByColumn("name", "age")
.of("Joe", "Andrus", "Joan", 18, 49, 32);You can also create DataFrames from collections or Streams (folded either by row or by column). Here is an example
of how to use a Stream of primitive ints, creating a DataFrame made of memory-efficient IntSeries columns:
DataFrame df = DataFrame
.foldByColumn("col1", "col2")
.ofStream(IntStream.range(0, 10000));col1 col2 ---- ---- 0 5000 1 5001 2 5002 ... 4997 9997 4998 9998 4999 9999 5000 rows x 2 columns
Finally, a DataFrame can be created from an array of Series, each Series representing a column:
DataFrame df = DataFrame
.byColumn("name", "age")
.of(
Series.of("Joe", "Andrus", "Joan"),
Series.ofInt(18, 49, 32)
);This is the most efficient way, as an array of Series is how each DataFrame is structured internally.
Index
Index is somewhat similar to Series. It serves as a DataFrame "header" and internally allows to quickly resolve
column String labels to their numeric positions. You’d work with Index instances outside a DataFrame only
occasionally, but it is still good to know its capabilities. E.g., here is how to get all the column labels:
String[] labels = df.getColumnsIndex().toArray();Printers
When doing data exploration and running data pipelines, it is important to be able to visualize data at every step.
More advanced forms of visualization include charts and diagrams. But the simplest thing you can do is printing
data to the console. Both DataFrame and Series implement toString() method, that will print their contents
as a single line, truncating large data sets in the process, which is good for debugging applications running on a
server.
A more human-friendly form of output is produced by a tabular printer. Here is how to use the default tabular printer:
DataFrame df = DataFrame
.foldByColumn("col1", "col2", "col3")
.ofStream(IntStream.range(0, 10000));
String table = Printers.tabular.toString(df);
System.out.println(table);It prints the data as follows, displaying at most 6 rows and truncating the rest. Same goes for cell values. Values longer than 30 chars are also truncated (since they are pretty short in our example, value truncation is not obvious here).
col1 col2 col3 ---- ---- ---- 0 3334 6668 1 3335 6669 2 3336 6670 ... 3331 6665 9999 3332 6666 0 3333 6667 0 3334 rows x 3 columns
You can change the truncation parameters by creating your own printer:
Printer printer = new TabularPrinter(3, 3); (1)
String table = printer.toString(df);
System.out.println(table);| 1 | Create a printer that displays at most 3 rows and up to 3 characters in each cell. |
c.. c.. c.. --- --- --- 0 3.. 6.. 1 3.. 6.. ... 3.. 6.. 0 3334 rows x 3 columns
If you are using Jupyter Notebook, all the printers are already setup for you. So if the last
statement in a Jupyter cell is a DataFrame or a Series, it will be printed as a table in the notebook.
|
Expressions
DFLib has a built-in expression language (implemented as a Java "DSL"). It allows to perform column-centric
operations on DataFrames and Series, such as data transformation, aggregation and filtering. Exp is the interface
representing an expression that takes either a DataFrame or a Series and produces a Series of the specified type.
To use expressions, you’d often start by adding a static import of the Exp interface, so that all its factory methods
are available directly in the code:
import static org.dflib.Exp.*;Now let’s create two simple expressions that return a named and a positional column of the requested type:
StrExp lastExp = $str("last");
DecimalExp salaryExp = $decimal(2);And now let’s evaluate the expressions:
DataFrame df = DataFrame.foldByRow("first", "last", "salary").of(
"Jerry", "Cosin", new BigDecimal("120000"),
"Juliana", "Walewski", new BigDecimal("80000"),
"Joan", "O'Hara", new BigDecimal("95000"));
Series<String> last = lastExp.eval(df);
Series<BigDecimal> salary = salaryExp.eval(df);This doesn’t look like much (other DFLib APIs would do the same), but this basic abstraction allows to describe a wide range of operations (filtering, sorting, aggregation, etc). Expressions are rarely evaluated standalone. More commonly they are passed as arguments to various other methods, as described below.
| DFLib expressions work on Series instead of individual values, so they can achieve the best possible performance for any given operation. Expressions should be the preferred way to manipulate your data instead of more "direct" APIs, such as custom lamdas. |
Now let’s look at various types of expressions…
Column Expressions
$str(..) and $decimal(..) expressions in the example above are the column lookup expressions. They return a DataFrame
column with a given name or at a given (zero-based) position without applying any transformations to the data.
| So what is returned when you evaluate a column expression with a Series object? Series can be thought of as a single (unnamed) column. So a column expression simply returns the Series unchanged, ignoring implied column name or position. |
Factory methods for column expressions are easy to spot in the Exp interface - they all start with a dollar sign:
$col("col"); (1)
(2)
$decimal("col");
$double("col");
$int("col");
$long("col");
(3)
$date("col");
$dateTime("col");
$time("col");
(4)
$bool("col");
$str("col");| 1 | Retrieves a column without implying a specific type |
| 2 | Retrieve columns that are expected to be numeric |
| 3 | Retrieve columns that are expected to be date/time |
| 4 | Retrieve columns of boolean or String types |
Return type is implied from the method name ($str(..) produces a Series<String>, $decimal(..) -
Series<BigDecimal>, $int(..) - Series<Integer>, $date(..) - Series<LocalDate> and so on).
To avoid overhead, column expressions do not perform any type conversions of the column data (with a notable exception
of $bool that does). So you need to pick the right type in your code based on your knowledge of data to avoid
ClassCastExceptions downstream, or use a generic $col(..) expression. If you do want to convert data from one type
to another, use one of the castAs methods explicitly:
$str("salary").castAsDecimal();castAs will do its best to provide a meaningful conversion to the target type. But sometimes it is simply not possible,
and it will throw an exception (e.g. a String like "abcd" can’t be converted to a number without some contextual knowledge).
In some other cases, no default conversion exists, but a custom conversion is possible and desired. You can do it via
Exp.mapVal(..).
Constant Expressions
If we want to generate a Series with the same repeating value, we can use the $val(..) expression:
Series<String> hi = $val("hi!").eval(df);hi! hi! hi!
A useful case for $val(..) is to create a separator for String concatenation:
Series<String> fn = concat( (1)
$str("first"),
$val(" "), (2)
$str("last")).eval(df);| 1 | This is a static import of Exp.concat(..), an expression that takes a variable number of arguments |
| 2 | Inserting space between first and last name |
Jerry Cosin Juliana Walewski Joan O'Hara
String Expressions
Numeric Expressions
$int(..), $long(..), double(..) and $decimal(..) columns expressions mentioned above are numeric (i.e. instances
of NumExp expression subclass), and as such, they provide arithmetics, comparison operations, and numeric aggregating
operations.
We will look at comparisons later in the "Conditions" chapter. Here is an example of arithmetics operation:
NumExp<?> exp = $int("c1")
.add($long("c2")) (1)
.div(2.); (2)
DataFrame df = DataFrame.foldByRow("c1", "c2").of(
1, 2L,
3, 4L)
.cols("c3").select(exp);| 1 | Add two columns |
| 2 | Multiply the result by a constant value |
c3 --- 1.5 3.5
| Associativity… Since expressions are built with Java API, there are no special associativity rules. Expressions are executed in the order they were chained together. In the example above, addition happens before division. |
Widening conversions… When we added values of int and long columns, the result was implicitly widened to long,
and later when it was divided by a double, the result became double. These conversions happen automatically and transparently
to the user. They follow regular Java rules for primitive numbers operations (with an addition of widening from
primitives to BigDecimal).
|
Here is an example of aggregating operations:
NumExp<?> exp = $int("c1")
.add($long("c2"))
.sum() (1)
.div(2.);
DataFrame df = DataFrame.foldByRow("c1", "c2").of(
1, 2L,
3, 4L)
.cols("c3").agg(exp);| 1 | Inserting an aggregating expression in a chain of arithmetic expressions produces an aggregated result |
c3 --- 5.0
Date Expressions
TODO
Complex Expressions
Expressions can be expanded by calling methods on the Exp object (and its type-specific subclasses). As we’ve already
seen above, expressions can be composed of other expressions by invoking static methods of Exp. E.g.:
(1)
Condition c = and( (2)
$str("last").startsWith("A"), (3)
$decimal("salary").add($decimal("benefits")).gt(100000.) (4)
);| 1 | "Condition" is an Exp<Boolean> described in more detail below |
| 2 | and(..) is a statically-imported Exp.and(..) |
| 3 | startsWith(..) produces a condition based on another string expression |
| 4 | add(..) produces an addition operation for two numeric expressions, gt(..) produces a condition from the result of the addition |
Conditions
TODO
Custom Expressions
Expression classes discussed above (Exp, StrExp, NumExp, etc.) define a large (and growing) number of operations,
yet there are always cases that require a custom transformation. There are a few flavors of expression factory methods
that take user-provided lambdas:
-
mapVal(..)- value-to-value transformationExp<byte[]> bytes = $decimal("col") .mapVal(d -> d.toBigInteger().toByteArray()); (1)1 the argument lambda takes a value and produces a value -
map(..)- Series-to-Series transformation. UnlikemapVal(..), allows a custom lambda to access the entireSeries, and in some cases, optimize the operation (e.g. by avoiding scanning through all values)Exp<Integer> exp = $int("col") .map(s -> Series.ofVal(s.get(0), s.size())); (1)1 the argument lambda takes the first value from the source Series, and produces the result Series of the same size filled with that value -
agg(..)- Series-to-value transformation. This expression is used in the "aggregating" context (such as group or window operations) where we need to produce a single value out of aSeries:
Exp<Integer> exp = $col("col")
.agg(s -> s.unique().size()); (1)| 1 | the argument lambda counts unique values in a series, taking a Series and producing an int. |
Sorters
Sorter is a special object, that allows to sort DFLib data structures. Internally a Sorter is using an
expression to retrieve values that comprise sorting criteria and index them in the specified order. Sorter can be
created from any expression by calling its asc() or desc() methods:
// sort by last name in the ascending order
Sorter s = $str("last").asc();
DFLib would allow you to create a Sorter based on any expression type. In runtime, the actual type must be
either a Java primitive or an instance of Comparable, or a ClassCastException will be thrown during sorting.
|
Column Operations
To manipulate data in a single DataFrame, with a few exceptions you would start by picking a subset of columns or
rows. Those are represented as ColumnSet and RowSet objects. Let’s look at columns first…
Pick Columns
Columns are picked either by condition, by name, by position or implicitly. Let’s take a look at each style…
By Condition
A condition is specified as a "predicate" lambda:
DataFrame df1 = df.cols(c -> !"middle".equals(c)).select();This form of cols(..) does not allow to reorder the columns. The resulting columns will always follow the relative
order of the original DataFrame:
first last ------- -------- Jerry Cosin Joan O'Hara
By Names
Here is a simple example of how to pick two columns from a DataFrame by name, and return a new DataFrame with just those two columns:
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Joan", "O'Hara", null);
DataFrame df1 = df
.cols("last", "first") (1)
.select(); (2)| 1 | Define a ColumnSet of two columns matching provided names.
The order of columns in the ColumnSet matches the order of column names passed to this method. |
| 2 | Return a new DataFrame matching the ColumnSet. More on this in the next chapter. |
last first -------- ------- Cosin Jerry O'Hara Joan
Passing names in a specific order to cols(..) allowed us to reorder the columns in the result.
|
Instead of listing included columns, you might specify which columns should be excluded from selection. This flavor doesn’t support reordering:
DataFrame df1 = df.colsExcept("middle").select();By Positions
You can also pick columns by positions. The first position is "0".
DataFrame df1 = df.cols(1, 0).select();Implicitly
If you specify no columns at all when building a ColumnSet, the returned DataFrame will be the same as the source one.
DataFrame df1 = df.cols().select();
In this particular case, implicit column selection is not very useful. But in fact, this style is dynamic
and may result in a smaller subset of columns selected based on the semantics of an operation applied to the
ColumnSet (e.g. named expressions making specific columns). Also, it allows to apply a transformation to
all columns at once. These cases are described later in the columns transformation chapter.
|
Rename Columns
We saw how we can select a subset of columns. While doing that, we can also assign new names to all or some of the
columns via selectAs(..).
Rename all column set columns:
DataFrame df1 = df
.cols("last", "first")
.selectAs("last_name", "first_name"); (1)| 1 | Passing new names for the ColumnSet columns. The order of the names must correspond to the order of columns
in the ColumnSet, regardless of how it was defined. |
last_name first_name --------- ---------- Cosin Jerry Walewski Juliana
Rename a subset of columns. Specifying names of all columns at once may not be practical for
"wide" column sets. Instead, you can pass a map of old to new names to selectAs(..) to rename just some columns.
Names not present in the map will remain unchanged:
DataFrame df1 = df
.cols("last", "first")
.selectAs(Map.of("last", "LAST_NAME"));LAST_NAME first --------- ------- Cosin Jerry O'Hara Joan
Rename with a function, applied to all column names in turn. This is useful e.g. to convert all names to lower or upper case:
DataFrame df1 = df
.cols("last", "first")
.selectAs(String::toUpperCase);LAST FIRST ------ ----- Cosin Jerry O'Hara Joan
Transform Columns
In the above examples we performed DataFrame vertical slicing, columns reordering and renaming. In this chapter
we’ll show how to transform column data.
Generating columns with expressions:
Exp fmExp = concat(
$str("first"),
ifNull($str("middle").mapVal(s -> " " + s), ""));
DataFrame df1 = df
.cols("first_middle", "last") (1)
.select(fmExp, $str("last")); (2)| 1 | When defining the ColumnSet, we are allowed to specify columns that are not present in the original DataFrame, as
we are naming the result columns, not the source columns. |
| 2 | For each column in the ColumnSet, there should be an expression that generates the column. The first expression
here transforms the data, the second simply picks a column from the source without modification. |
first_middle last ------------ ------ Jerry M Cosin Joan O'Hara
Generating columns row-by-row with RowMapper:
RowMapper mapper = (from, to) -> {
String middle = from.get("middle") != null
? " " + from.get("middle")
: "";
to.set(0, from.get("first") + middle).set(1, from.get("last"));
};
DataFrame df1 = df
.cols("first_middle", "last")
.select(mapper);There’s also a way to generating columns row-by-row with per-column array of RowToValueMapper. It is not very different
from what we’ve seen so far, so we are leaving this as an exercise for the reader.
Split Columns
Values can be split using an expression into iterable or array elements, and new columns can be generated
from those elements, thus "expanding" each row. Here is an example of handling Lists of values (List is, of course,
an Iterable) :
DataFrame df = DataFrame.foldByRow("name", "phones").of(
"Cosin", List.of("111-555-5555","111-666-6666","111-777-7777"),
"O'Hara", List.of("222-555-5555"));
DataFrame df1 = df
.cols("primary_phone", "secondary_phone")
.selectExpand($col("phones")); (1)| 1 | selectExpand(..) takes an expression that returns a column with lists. If each List has more than 2 numbers,
the rest are ignored, if less - nulls are used for the missing elements |
primary_phone secondary_phone ------------- --------------- 111-555-5555 111-666-6666 222-555-5555 null
If you don’t know the exact number of phones, but would like to capture them all in separate columns, do not specify any explicit names (as mentioned in the implicit column selection chapter). As many columns as needed to fit the longest array of phone numbers will be generated on the fly, and the names will be assigned dynamically:
DataFrame df1 = df
.cols() (1)
.selectExpand($col("phones"));| 1 | Not specifying any columns will result in split columns generated dynamically. |
0 1 2 ------------ ------------ ------------ 111-555-5555 111-666-6666 111-777-7777 222-555-5555 null null
If the phone numbers were provided as a comma-separated String instead of a List, you can split the String into an
array of numbers using the split(..) expression, and use selectExpandArray(..) to generate the columns:
DataFrame df = DataFrame.foldByRow("name", "phones").of(
"Cosin", "111-555-5555,111-666-6666,111-777-7777",
"O'Hara", "222-555-5555");
DataFrame df1 = df
.cols("primary_phone", "secondary_phone")
.selectExpandArray($str("phones").split(','));Merge Columns
The ColumnSet operations demonstrated so far resulted in discarding the source DataFrame, and returning only the
columns defined within the set. But often we would like to recombine transformed ColumnSet with the original
DataFrame. Any in-place data cleanup, data set enrichment, etc. fall in this category.
Of course, we call them "in-place" only in a logical sense, as DataFrame is immutable, and all modifications
result in creation of a new instance.
|
For this ColumnSet provides a number of "merging" methods. All the ColumnsSet methods that do not start with
select… are performing a merge with the source DataFrame. In fact, all the renaming and data transformation
operations that we just discussed can also be executed as "merges".
Here is an example of cleaning up a data set and adding a new column:
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"jerry", "cosin", "M",
"Joan", "O'Hara", null);
Function<String, Exp<String>> cleanup = col -> $str(col).mapVal(
s -> s != null && !s.isEmpty()
? Character.toUpperCase(s.charAt(0)) + s.substring(1)
: null); (1)
DataFrame df1 = df
.cols("last", "first", "full") (2)
.merge( (3)
cleanup.apply("last"),
cleanup.apply("first"),
concat($str("first"), $val(" "), $str("last"))
);| 1 | An expression that capitalizes the first letter of the name |
| 2 | The columns we are going to generate or transform |
| 3 | Instead of select(..), use merge(..) to combine columns with the original DataFrame |
Now let’s check the result. The first two columns in the ColumnSet ("last", "first") were already present in the
DataFrame, so they got replaced with the cleaned up versions. The last column ("full") was new, so it was appended to
the right side of the DataFrame:
first last middle full ----- ------ ------ ----------- Jerry Cosin M jerry cosin Joan O'Hara null Joan O'Hara
General merge rules:
-
Merging is done by name. DataFrame’s columns with matching names are replaced with new versions, columns that are not a part of the
ColumnSetare left unchanged, and columns in theColumnSet, but not in the DataFrame, are appended on the right. -
The order of the existing columns in the
ColumnSethas no effect on the order of replaced columns (i.e. they are placed in their original positions). The relative order of appended columns is respected. -
All transformation operations (such as expressions in our example) are applied to the original DataFrame columns (and can reference those outside the
ColumnSet), but do not see the transformed columns. This is why there is a lowercase name in the resulting "full" column.
What if we want to ensure that all of the ColumnSet columns are appended, and no replacement of the original columns
occurs? For this you can manually specify ColumnSet labels that are not found in the source DataFrame, or you can use
DataFrame.colsAppend(..), and DFLib itself will ensure that the names are unique, appending _ to each label until
it doesn’t overlap with anything already in the DataFrame:
DataFrame df1 = df
.colsAppend("last", "first") (1)
.merge(
cleanup.apply("last"),
cleanup.apply("first")
);| 1 | Using colsAppend(..) instead of cols() ensures that both pre- and post-cleanup columns are preserved. |
first last middle last_ first_ ----- ------ ------ ------ ------ jerry cosin M Cosin Jerry Joan O'Hara null O'Hara Joan
Since we’ve already discussed various flavors of column renaming and transformation in the context of select(..),
we leave it as an exercise for the user to explore their "merging" counterparts - as(..), map(..), expand(..), etc.
|
Compact Columns
This transformation converts columns to primitives. The values in the columns to be converted can be Numbers, Booleans
or Strings (or objects with toString() that can be parsed to a primitive type):
DataFrame df = DataFrame.foldByRow("year", "sales").of(
"2022", "2005365.01",
"2023", "4355098.75");
DataFrame df1 = df
.cols("year").compactInt(0) (1)
.cols("sales").compactDouble(0.);| 1 | The argument to compact is the primitive value to use if the value being converted is null |
compactInt(..), compactDouble(..) and other similar methods are not just syntactic sugar. They convert
DataFrame columns to primitive Series, that take significantly less memory (hence, the name "compact") and compute
most operations faster than Object-based Series. So you should consider using them where possible.
|
Fill Nulls
As a part of a dataset cleanup effort, you might want to replace null values with something meaningful. For this you
may have to guess or maybe extrapolate the existing values based on some internal knowledge of the dataset. To help with
this task, ColumnSet provides a few methods discussed here.
Filling nulls with a constant value:
DataFrame df = DataFrame.foldByRow("c1", "c2").of(
"a1", "a2",
null, null,
"b1", "b2");
DataFrame clean = df.cols("c1", "c2").fillNulls("X");c1 c2 -- -- a1 a2 X X b1 b2
Filling nulls with values adjacent to the cells with nulls:
DataFrame clean = df
.cols("c1").fillNullsBackwards() (1)
.cols("c2").fillNullsForward(); (2)| 1 | fillNullsForward(..) takes a non-null value preceding the null cell and uses it to replace nulls. |
| 2 | fillNullsBackwards(..) uses the first non-null value following the null cell. |
c1 c2 -- -- a1 a2 b1 a2 b1 b2
There’s also a way to fill nulls from another Series object used as a "mask" :
Series<String> mask = Series.of("A", "B", "C", "D");
DataFrame clean = df.cols("c1", "c2").fillNullsFromSeries(mask);c1 c2 -- -- a1 a2 B B b1 b2
The "mask" Series can be longer or shorter than the DataFrame height. Values are aligned by position
starting at zero.
|
Finally, we can use an Exp to calculate values for nulls:
DataFrame df = DataFrame.foldByRow("c1", "c2").of(
"a1", "a2",
null, null,
"b1", "b2");
DataFrame clean = df.cols("c1", "c2")
.fillNullsWithExp(rowNum()); (1)
| 1 | Exp.rowNum() generates a Series with row numbers, so the nulls are replaced by the number denoting their position
in the DataFrame: |
c1 c2 -- -- a1 a2 2 2 b1 b2
Drop Columns
To get rid of certain columns in a DataFrame, you can either select the columns you would want to drop and call drop()
or select the columns you’d want to remain and call select():
DataFrame df1 = df.cols("middle").drop();DataFrame df1 = df.colsExcept("middle").select();In both cases, the result is the same:
first last ----- ------ Jerry Cosin Joan O'Hara
Understanding ColumnSet
Now that we’ve seen various ways how you can pick, rename and transform columns, let’s look at ColumnSet as a whole.
It is important to understand that no matter how a ColumnSet was created, its columns are always the result columns
of the operation, not the source DataFrame columns. They often reference names and positions of the source
columns and, in some cases, their values are copied directly from the source, but logically they always specify the result.
To illustrate the point, let’s first look a direct source-to-result copy example:
DataFrame df = DataFrame.foldByRow("first", "last").of(
"Jerry", "Cosin",
"Joan", "O'Hara");
DataFrame df1 = df
.cols("last", "first")
.select();We can change it a little, by adding a column to the ColumnSet that is not in the original
DataFrame, and it will still work (with the new column being filled with nulls):
DataFrame df1 = df
.cols("last", "first", "middle")
.select();last first middle ------ ----- ------ Cosin Jerry null O'Hara Joan null
Even when renaming, we are technically renaming ColumnSet columns (that may or may not come from the source), not the
source columns:
DataFrame df1 = df
.cols("last", "first", "middle")
.selectAs("L", "F", "M");L F M ------ ----- ---- Cosin Jerry null O'Hara Joan null
Row Operations
Just like with columns, row operations first define a RowSet, execute some transformation, and then are either
merged back with the original DataFrame, or "selected" as a standalone one. RowSet and ColumnSet have other
similarities (e.g. the ability to evaluate expressions by column, and create RowColumnSet), but RowSet is also
rather different in how its rows are picked and what other operations are available.
The important similarity with ColumnSet is that RowSet rows, while often referencing source rows, always
define the result rows. See "Understanding ColumnSet" for a more detailed discussion.
|
Pick Rows
Rows are picked either by condition, by positions or as a range. Let’s take a look at each style…
By Condition
A Condition (a boolean Exp) can be used to pick matching rows:
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Joan", "O'Hara", "P");
DataFrame df1 = df
.rows($str("last").startsWith("W").eval(df)) (1)
.select(); (2)| 1 | Applies a Condition to the DataFrame, to include matching rows in the RowSet. |
| 2 | Returns a new DataFrame matching the RowSet |
first last middle ------- -------- ------ Juliana Walewski null
Another form of condition is a "predicate" lambda (a RowPredicate object), evaluated row-by-row:
DataFrame df1 = df
.rows(r -> r.get("last", String.class).startsWith("W"))
.select();A condition can be precalculated as a BooleanSeries. A common scenario is calling locate() on another Series
or a DataFrame / RowSet to build a BooleanSeries "selector", and then using it to pick rows from another DataFrame:
IntSeries salaries = Series.ofInt(100000, 50000, 45600); (1)
BooleanSeries selector = salaries.locateInt(s -> s > 49999); (2)
DataFrame df1 = df.rows(selector).select();| 1 | A Series of salaries with elements positions matching row positions in the persons DataFrame. |
| 2 | Precalculates a reusable "selector" |
first last middle ------- -------- ------ Jerry Cosin M Juliana Walewski null
By Positions
Here is an example of RowSet defined using an array of row positions.
DataFrame df1 = df
.rows(2, 0, 2) (1)
.select();| 1 | An int[] that defines a RowSet |
first last middle ----- ------ ------ Joan O'Hara P Jerry Cosin M Joan O'Hara P
| An array of positions is also a kind of "condition". The main difference is that it allows to reorder rows by specifying positions in a desired sequence and/or duplicate rows by referencing the same position more than once. Both features are demonstrated in the example above. |
Instead of an array, positions can be defined as an IntSeries "index". Just like with conditions, it is often
calculated from another Series or DataFrame / RowSet:
IntSeries selector = salaries.indexInt(s -> s > 49999); (1)
DataFrame df1 = df.rows(selector).select();| 1 | Precalculates a reusable "selector" with positions. Uses a Series of salaries that is not a part of "our" DataFrame |
first last middle ------- -------- ------ Jerry Cosin M Juliana Walewski null
As a Range
Finally, rows can be selected as a continuous range of row positions:
DataFrame df1 = df
.rowsRange(0, 2) (1)
.select();| 1 | The range is defined by two ints: its starting index and the index, following its last index. |
first last middle ------- -------- ------ Jerry Cosin M Juliana Walewski null
Transform Rows
Just like ColumnSet, RowSet defines a number of column- and row-based transformations. And just like with
ColumnSet, each transformation can be invoked as a "select" or a "merge", returning either the RowSet rows or all
rows from the original DataFrame. Here we will demonstrate selecting operations, and will talk about merging next.
Transforming with column expressions:
DataFrame df = DataFrame.foldByRow("last", "age", "retires_soon").of(
"Cosin", 61, false,
"Walewski", 25, false,
"O'Hara", 59, false);
DataFrame df1 = df
.rows($int("age").mapBoolVal(a -> 67 - a < 10))
.select(
$col("last"),
$col("age"),
$val(true)); (1)| 1 | Select the rows from each column without changes, except the last one, where we flip the "retires_soon" flag to "true". |
last age retires_soon ------ --- ------------ Cosin 61 true O'Hara 59 true
We had to specify an expression for every column in the DataFrame, even though only a single column got transformed.
This code can be improved by creating a RowColumnSet described here.
|
Transforming row-by-row with RowMapper:
RowMapper mapper = (from, to) -> {
from.copy(to);
to.set("retires_soon", true);
};
DataFrame df1 = df
.rows($int("age").mapBoolVal(a -> 67 - a < 10))
.select(mapper);There’s also a way to transforming row-by-row with per-column array of RowToValueMapper. It is not very different
from what we’ve seen so far, so we are leaving this as an exercise for the reader.
Merge Rows
If we want to merge the result of a RowSet transformation to the original DataFrame, we’ll need to use methods
like merge(..) (i.e. those that do not start with select):
DataFrame df = DataFrame.foldByRow("last", "age", "retires_soon").of(
"Cosin", 61, false,
"Walewski", 25, false,
"O'Hara", 59, false);
DataFrame df1 = df
.rows($int("age").mapBoolVal(a -> 67 - a < 10))
.merge(
$col("last"),
$col("age"),
$val(true));last age retires_soon -------- --- ------------ Cosin 61 true Walewski 25 false O'Hara 59 true
Merging rows is done similar to columns, except rows have no name labels, so it is done by position. General merge rules:
-
Merging is done by row position. DataFrame rows with matching positions are replaced with transformed versions, rows that are not a part of the
RowSetare left unchanged, and rows in theRowSet, but not in theDataFrame(e.g., intentionally duplicated rows or split rows) are appended in the bottom. -
The order of the existing rows in the
RowSethas no effect on the order of replaced rows (i.e. they are placed in their original positions). The relative order of added rows is respected.
Just like with columns, for most RowSet.select(..) methods there are "merging" counterparts, such as map(..),
expand(..), unique(..), etc.
|
Split Rows
Splitting rows is somewhat simpler than splitting columns. The API takes a single column (no expression is allowed), and splits any expandable values into new rows:
DataFrame df = DataFrame.foldByRow("name", "phones").of(
"Cosin", List.of(
"111-555-5555",
"111-666-6666",
"111-777-7777"),
"O'Hara", List.of("222-555-5555"));
DataFrame df1 = df
.rows()
.selectExpand("phones");name phones ------ ------------ Cosin 111-555-5555 Cosin 111-666-6666 Cosin 111-777-7777 O'Hara 222-555-5555
| The expansion column can contain scalars, arrays or iterables. |
Unique Rows
To deduplicate DataFrames, there’s an API to select fully or partially-unique rows. Uniqueness is checked either on all columns of each row, or a preselected subset:
DataFrame df = DataFrame.foldByRow("first", "last").of(
"Jerry", "Cosin",
"Jerry", "Jones",
"Jerry", "Cosin",
"Joan", "O'Hara");
DataFrame df1 = df.rows().selectUnique(); (1)| 1 | Keep only fully unique rows |
first last ----- ------ Jerry Cosin Jerry Jones Joan O'Hara
DataFrame df2 = df.rows().selectUnique("first"); (1)| 1 | Deduplicate first names. Picking the row of each earliest-encountered unique first name. |
first last ----- ------ Jerry Cosin Joan O'Hara
Drop Rows
To get rid of certain rows in a DataFrame, you can either select the rows you would want to drop, and call drop()
or select the rows you’d want to remain and call select():
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Joan", "O'Hara", "P");
DataFrame df1 = df.rows($col("middle").isNull()).drop();DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Joan", "O'Hara", "P");
DataFrame df1 = df.rowsExcept($col("middle").isNull()).select();In both cases, the result is the same:
first last middle ----- ------ ------ Jerry Cosin M Joan O'Hara P
Row and Column Operations
TODO
Pick Rows and Columns
TODO
Transform Rows and Columns
TODO
Merge Rows and Columns
TODO
Drop Rows and Columns
Head and Tail
As we’ve seen previously, most operations within a single DataFrame are performed on row and column sets. Still, some
are applied to the DataFrame directly. head and tail are such examples.
When you only need the "first N" or "last M" rows of a DataFrame (or values of a Series) you can use head and tail
operations. Here is how to get the top 2 rows of a DataFrame:
DataFrame df = DataFrame.foldByRow("first", "last").of(
"Jerry", "Cosin",
"Juliana", "Walewski",
"Joan", "O'Hara");
DataFrame df1 = df.head(2); (1)| 1 | Returns a new DataFrame with two top rows of the original DataFrame. |
first last ------- --------- Jerry Cosin Juliana Walewski
tail works similarly, but returns the last N rows:
DataFrame df1 = df.tail(1);first last ----- ------ Joan O'Hara 1 row x 2 columns
The argument to either head(..) or tail(..) can be negative.
In which case the operation skips the specified number of elements either from the top or from the bottom, and returns the remaining elements.
The following code returns a new DataFrame after skipping the two top rows of the original DataFrame:
DataFrame df1 = df.head(-2);first last ------ --------- Joan O'Hara 1 row x 2 columns
Unlike index operations on arrays and lists in Java, head(..) and tail(..) are safe in regards to bounds checking.
They DO NOT throw exceptions when the length parameter is bigger than DataFrame height (or Series size), returning an empty DataFame (or Series) instead.
|
Series also define head(..) and tail(..) that do what you’d expect, returning first or last N values.
|
Sorting
You can sort values in Series, and sort rows in DataFrames. As is the case everywhere else in DFLib, sorting does
not alter the original object, and instead creates a new instance of either Series or DataFrame.
First let’s look at sorting Series…
Sort Series
Series provides a sort method to sort its data using a sorter built from an expression:
// sort series by String length
Series<String> s = Series
.of("12", "1", "123")
.sort($str("").mapVal(String::length).asc());The result is a new Series with sorted data:
1 12 123 3 elements
Alternatively the same can be achieved using a Comparator:
Series<String> s = Series
.of("12", "1", "123")
.sort(Comparator.comparingInt(String::length));The next example shows how to sort Series in the "natural" order (alphabetically for Strings):
Series<String> s = Series
.of("c", "d", "a")
.sort($str("").asc());a c d 3 elements
Series of primitives have methods to sort values in the natural order without an explicit sorter or comparator:
LongSeries s = Series
.ofLong(Long.MAX_VALUE, 15L, 0L)
.sortLong(); 0
15
9223372036854775807
3 elements
Additionally, IntSeries has an optimized method to sort ints with a custom IntComparator.
Next we’ll check how to sort a DataFrame.
Sort DataFrame
Rows in a DataFrame can be sorted with one or more sorters.
Just like in other places where a Sorter might be
used, there is an assumption that the Sorter expression produces values that are either Java primitives or are
compatible with java.lang.Comparable (i.e., Strings, numbers, etc).
|
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Jerry", "Albert", null,
"Joan", "O'Hara", "J");
DataFrame df1 = df.sort(
$str("first").asc(),
$str("last").asc());first last middle ------- --------- ------ Juliana Walewski null Jerry Albert null Jerry Cosin M Joan O'Hara J
Alternatively sorting can be done by a single column name or an array of columns. The assumption is the same as above
- values in columns used for sorting must be either Java primitive or implement java.lang.Comparable.
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Joan", "O'Hara", "J");
DataFrame df1 = df.sort("first", true); (1)| 1 | The first argument is the column name (can also be column integer index), the second - a boolean indicating sort
direction (true for ascending, false - for descending order). |
DataFrame df = DataFrame.foldByRow("first", "last", "middle").of(
"Jerry", "Cosin", "M",
"Juliana", "Walewski", null,
"Jerry", "Albert", null,
"Joan", "O'Hara", "J");
DataFrame df1 = df.sort(new String[]{"last", "first"}, new boolean[]{true, false});Concatenation
There are various ways to combine data from multiple Series or DataFrames. The simplest is concatenation,
described in this chapter. Series can be concatenated together producing a longer Series. DataFrames can be concatenated
either vertically (along the rows axis) or horizontally (along the columns axis).
Concatenate Series
If you have a Series object and want to concatenate it with one or more other Series, you’d use Series.concat(..)
method:
Series<String> s1 = Series.of("x", "y", "z");
Series<String> s2 = Series.of("a");
Series<String> s3 = Series.of("m", "n");
Series<String> sConcat = s1.concat(s2, s3);The result is as expected contains values of all Series put together:
x y z a m n 6 elements
If you have a collection or an array of Series and want to "glue" them together, you can use a static
SeriesConcat.concat(..):
Collection<Series<String>> ss = asList(
Series.of("x", "y", "z"),
Series.of("a"),
Series.of("m", "n"));
Series<String> sConcat = SeriesConcat.concat(ss);The result is the same as in the previous example. Also you can concatenate Series with itself:
Series<String> s = Series.of("x", "y");
Series<String> sConcat = s.concat(s);x y x y 4 elements
Concatenate DataFrames
DataFrame offers two options for concatenation - vertical (stacking DataFrames on top of each other) and horizontal (putting them next to each other). Let’s see some examples..
DataFrame df1 = DataFrame.foldByRow("a", "b").of(
1, 2,
3, 4);
DataFrame df2 = DataFrame.foldByRow("a", "b").of(
5, 6,
7, 8);
DataFrame dfv = df1.vConcat(df2); (1)| 1 | Concatenate this and another DataFrame vertically. The argument is a vararg, so more than one DataFrame can be passed to the method. |
a b - - 1 2 3 4 5 6 7 8
DataFrame dfh = df1.hConcat(df2); (1)| 1 | Concatenate this and another DataFrame horizontally. The argument is a vararg, so more than one DataFrame can be passed to the method. |
a b a_ b_ - - -- -- 1 2 5 6 3 4 7 8
Since both df1 and df2 had the same column names, and a DataFrame must only have unique columns, _ suffix was
automatically appended to the conflicting columns in the resulting DataFrame. We will see this auto-renaming behavior
in other places, such as joins.
|
So far all our concatenation examples consisted of DataFrames that had matching dimensions (same number and names of
columns for vConcat and same number of rows for hConcat). But what if concatenated DataFrames are shaped or named
differently?
Concat methods may take an extra "how" parameter to define concatenation semantics. The type of the "how" parameter is
JoinType, and can be one of inner (default), left, right, full.
We’ll see JoinType again soon when discussing joins. Concatenation and joins are related fairly
closely.
|
Let’s look how this works with vConcat:
DataFrame df1 = DataFrame.foldByRow("b", "a").of(
1, 2,
3, 4);
DataFrame df2 = DataFrame.foldByRow("a", "c").of( (1)
5, 6,
7, 8);
DataFrame dfv = df1.vConcat(JoinType.inner, df2); (2)| 1 | df1 column names are "b" and "c", while df2 - "a" and "c". |
| 2 | Explicitly passing JoinType.inner to vConcat. It is done to demonstrate the point. Since inner is the
default, omitting it will not change the outcome. |
a - 2 4 5 7
As you can see in the result, the behavior of inner join is to only keep columns that are present in both df1 and
df2. Columns are joined by name, regardless of their order (though the order of columns is preserved in the result,
following the order in each DataFame being joined, left to right).
Changing semantics from inner to left gives us all the columns of the leftmost DataFrame, but those columns that
are missing from the concatenated DataFrame are filled with nulls in the corresponding positions:
DataFrame dfv = df1.vConcat(JoinType.left, df2);b a ---- - 1 2 3 4 null 5 null 7
Leaving it as an exercise for the reader to try right and full joins.
hConcat works similarly, however concatenation is done by row position, as there are no row names:
DataFrame df1 = DataFrame.foldByRow("a", "b").of(
1, 2,
3, 4,
5, 6);
DataFrame df2 = DataFrame.foldByRow("c", "d").of(
7, 8,
9, 10);
DataFrame dfv = df1.hConcat(JoinType.left, df2);a b c d - - ---- ---- 1 2 7 8 3 4 9 10 5 6 null null
Joins
If you worked with relational databases, you know what "joins" are. This is a way to combine related rows from
multiple tables. DataFrames can be joined together, just like two DB tables. DFLib provides 4 familiar flavors of joins:
inner, left (outer), right (outer) and full (outer).
Inner Joins
DataFrame left = DataFrame
.foldByRow("id", "name")
.of(1, "Jerry", 2, "Juliana", 3, "Joan");
DataFrame right = DataFrame
.foldByRow("id", "age")
.of(2, 25, 3, 59, 4, 40);
DataFrame joined = left
.join(right) (1)
.on("id") (2)
.select();| 1 | join(..) is equivalent to innerJoin(..) (just like in SQL). With "inner" semantics, only the matching rows that
are present in both DataFrames will be included in the result below. |
| 2 | Columns used in the join criteria have the same name in both DataFrames, so we can specify the name of the join column only once. In general, the names do not need to match, and multiple columns can participate in a join. |
id name id_ age -- ------- --- --- 2 Juliana 2 25 3 Joan 3 59
Column Namespace
Notice how DFLib treated the id column in the join result above. Since it was present in both left and right DataFrames,
it was included in the result twice, but the second instance was renamed to id_ to avoid a naming collision. The same
renaming would occur for any other columns from the right DataFrame that have conflicting names with the columns from
the left. A quick way to get rid of duplicate columns is to exclude them from the result using the name pattern:
DataFrame joined = left
.join(right)
.on("id")
.colsExcept(c -> c.endsWith("_"))
.select();id name age -- ------- --- 2 Juliana 25 3 Joan 59
You may have noticed that colsExcept(..).select() style of picking join columns is very similar to the
column set API. The main difference is that the Join object itself represents a special form of column
set, and only "select" operations are available.
|
For better clarity, you can assign names to the left and/or the right DataFrames just before the join, and the
column names in the result will be prefixed with the corresponding DataFrame name, thus avoiding the trailing underscore:
DataFrame joined = left.as("L") (1)
.join(right.as("R")) (2)
.on("id")
.select();| 1 | Assign the name to the left DataFrame |
| 2 | Assign the name to the right DataFrame |
This makes it easier to identify the origin of each column.
L.id L.name R.id R.age ---- ------- ---- ----- 2 Juliana 2 25 3 Joan 3 59
DataFrame immutability applies to name assignments as well. Calling .as() creates a separate
DataFrame, so the original one remains unnamed.
|
Transform Columns
When building the join result, you can apply expressions to alter the existing columns or create new columns all together:
DataFrame joined = left.as("L")
.join(right.as("R"))
.on("id")
.cols("name", "retires_soon")
.select(
$col("name"),
$int("R.age").gt(57)
);name retires_soon ------- ------------ Juliana false Joan true
In the context of a join, column expressions can reference either short column names of left and right
DataFrames, or the fully qualified ones with the prefix. In the former case, the names should take into account the "_"
suffix applied to the right DataFrame columns when their names overlap with column names on the left.
|
Outer Joins
Now let’s demonstrate outer joins. Here is a leftJoin(..) example using the same left and right DataFrames:
DataFrame joined = left
.leftJoin(right)
.on("id")
.select();id name id_ age -- ------- ---- ---- 1 Jerry null null 2 Juliana 2 25 3 Joan 3 59
It has all the rows from the left DataFrame, and only the matching rows from the right DataFrame. For left rows with no
matching right rows, the right columns are filled with null.
Indicator Column
Join API allows to explicitly identify which rows had a match, and which didn’t by adding a special "indicator" column.
Let’s show it on a fullJoin(..) example:
DataFrame joined = left
.fullJoin(right)
.on("id")
.indicatorColumn("join_type") (1)
.colsExcept(c -> c.endsWith("_"))
.select();| 1 | Request an indicator column with a user-specified name. |
id name age join_type ---- ------- ---- ---------- 1 Jerry null left_only 2 Juliana 25 both 3 Joan 59 both null null 40 right_only
The join_type column will contain a special enum of org.dflib.join.JoinIndicator type that allows to categorize rows
in the produced DataFrame.
indicator column can be requested for all join types, but it is only useful for the three outer joins (it will
always be both for inner joins).
|
Nested Loop Joins
The joins we’ve seen so far were all based on comparing left and right column values. They are knows as "hash joins", and are usually as fast as joins can get. However, they can not express every possible condition, and sometimes we have to resort to another kind of joins - "nested loop", that would compare every row from the left DataFrame to every row from the right. For instance, let’s join a DataFrame of salaries with itself to produce pairs of names - a person with higher salary on the left vs. everyone with lower salary on the right:
DataFrame df = DataFrame.foldByRow("name", "salary").of(
"Jerry", 120000,
"Juliana", 80000,
"Joan", 95000);
JoinPredicate p = (r1, r2) ->
((Integer) r1.get("salary")) > ((Integer) r2.get("salary"));
DataFrame joined = df
.leftJoin(df)
.predicatedBy(p) (1)
.select()
.sort($int("salary").desc(), $int("salary_").desc()) (2)
.cols("name", "name_").selectAs("makes_more", "makes_less");| 1 | Custom join condition |
| 2 | Sorting and renaming the result columns for a user-friendly display |
makes_more makes_less ---------- ---------- Jerry Joan Jerry Juliana Joan Juliana Juliana null
| Nested loop joins are much slower, and should be avoided unless absolutely necessary. |
Group and Aggregate
DataFrame rows can be combined into groups based on common column values. For instance, here is a payroll report that contains payments to employees over time:
name amount date ---------------- ------ ---------- Jerry Cosin 8000 2024-01-15 Juliana Walewski 8500 2024-01-15 Joan O'Hara 9300 2024-01-15 Jerry Cosin 4000 2024-02-15 Juliana Walewski 8500 2024-02-15 Joan O'Hara 9300 2024-02-15 Jerry Cosin 8000 2024-03-15 Joan O'Hara 9300 2024-03-15
We can group it by date like this:
GroupBy groupBy = df.group("date"); (1)| 1 | Here we are grouping by a single column, but multiple columns can be specified as well |
GroupBy object has a number of useful operations to transform grouped data. The most common one is aggregation of
values to produce one row per group (similar to SQL GROUP BY clause). E.g., we can calculate some statistics about
each payroll period by passing a list of "aggregating" expressions to the agg(..) method:
DataFrame agg = df
.group("date")
.agg(
$col("date").first(), (1)
$double("amount").sum(), (2)
count() (3)
);| 1 | first(..) expression is applied to the column used in the grouping. As each value within the group is the same,
we can simply select the first one for our aggregated row |
| 2 | This calculates total payroll amount within each group |
| 3 | count() returns the number of rows in each group |
date sum(amount) count ---------- ----------- ----- 2024-01-15 25800.0 3 2024-02-15 21800.0 3 2024-03-15 17300.0 2
first(..), sum(..) and count() are special "aggregating" expressions. Unlike the "normal" expressions that produce
Series of the same size as input Series, aggregating ones output Series with single values. Hence,
the number of rows in the aggregated DataFrame is equal to the number of groups in GroupBy. There are more aggregating
expressions that can concatenate values within a group, calculate min, max, avg values, etc.
Let’s make a minor improvement to the example above and provide more descriptive column names:
DataFrame agg = df
.group("date")
.cols("date", "total", "employees")
.agg(
$col("date").first(),
$double("amount").sum(),
count()
);date total employees ---------- ------- --------- 2024-01-15 25800.0 3 2024-02-15 21800.0 3 2024-03-15 17300.0 2
There’s a similarity between GroupBy.cols(..) method and DataFrame.cols(..). And, as we’ll see in the later
examples, a few more methods (select(..) and map(..)) work the same as in ColumnSet. So GroupBy is essentially
a ColumnSet with operations applied per group.
|
Instead of aggregating groups, we can select back the original rows, but apply some group-specific transformations. E.g. we can do row ranking within groups. Here we’ll rank employees by their salary amount vs other employees in the same period:
DataFrame ranked = df.group("date")
.sort($double("amount").desc()) (1)
.cols("date", "name", "rank")
.select( (2)
$col("date"),
$col("name"),
rowNum() (3)
);| 1 | To produce a proper ranking, we need to order rows within each group first |
| 2 | In select(..), instead of aggregating expressions, we are using "normal" ones , but they are applied to
each group separately. |
| 3 | Ranking function applied within each group |
date name rank ---------- ---------------- ---- 2024-01-15 Joan O'Hara 1 2024-01-15 Juliana Walewski 2 2024-01-15 Jerry Cosin 3 2024-02-15 Joan O'Hara 1 2024-02-15 Juliana Walewski 2 2024-02-15 Jerry Cosin 3 2024-03-15 Joan O'Hara 1 2024-03-15 Jerry Cosin 2
The resulting DataFrame has the same number of rows as the original one, but the ordering is different, and the columns are the ones that we requested.
We can use GroupBy.head(..) and (tail(..)) to find top-paid employees within each payroll period. Notice,
that this operation doesn’t do any aggregation. Just sorting within groups and picking the top results:
DataFrame topSalary = df.group("date")
.sort($double("amount").desc()) (1)
.head(1) (2)
.select();| 1 | Do the same sorting as before |
| 2 | Pick the top row in each group |
name amount date ----------- ------ ---------- Joan O'Hara 9300 2024-01-15 Joan O'Hara 9300 2024-02-15 Joan O'Hara 9300 2024-03-15
Window Operations
Window operations are somewhat close to "group", except they usually preserve the rows of the original
DataFrame and may add extra columns with values calculated from "windows" of data relative to a given row. We’ll use
the following DataFrame to demonstrate how window operations work:
name amount date ---------------- ------ ---------- Jerry Cosin 8000 2024-01-15 Juliana Walewski 8500 2024-01-15 Joan O'Hara 9300 2024-01-15 Jerry Cosin 8800 2024-02-15 Juliana Walewski 8500 2024-02-15 Joan O'Hara 9500 2024-02-15
A window is created by calling over() on the DataFrame:
Window window = df.over();Here is a full operation that adds a "max_salary" column to each employee:
DataFrame df1 = df
.over()
.partitioned("name") (1)
.cols("max_salary").merge($int("amount").max()); (2)| 1 | Defines DataFrame "partitioning". Calculation window for each row will be all the rows in the same partition |
| 2 | Defines a new column and an aggregating expression to produce values. |
name amount date max_salary ---------------- ------ ---------- ---------- Jerry Cosin 8000 2024-01-15 8800 Juliana Walewski 8500 2024-01-15 8500 Joan O'Hara 9300 2024-01-15 9500 Jerry Cosin 8800 2024-02-15 8800 Juliana Walewski 8500 2024-02-15 8500 Joan O'Hara 9500 2024-02-15 9500
Partitioning in the example above is similar to "group" in GroupBy. Another way to define windows is via a range(..)
method that allows to build window with fixed offset relative to each row.
TODO
Pivot
TODO
Stack
TODO
User-Defined Functions
User-defined functions (aka "UDF") is a way to create highly-reusable expressions. Expressions are, of course, abstract transformations of columns, so they are already somewhat reusable. However, they encode names (or positions) of all columns they operate on. So you won’t be able to apply the same expression to two different sets of columns in the same DataFrame. UDFs are intended to address this limitation and make expressions fully dynamic.
As the name implies, a UDF is a function (usually implemented as a lambda or a method ref). It takes one or more expressions as parameters, and produces a single expression:
void formatNames() {
DataFrame df = DataFrame.foldByRow("first", "last").of(
"JERRY", "COSIN",
"juliana", "waLEwsKi");
Udf1<String, String> formatName = e ->
e.castAsStr().mapVal(this::formatName); (1)
DataFrame clean = df.cols("first", "last").merge(
formatName.call("first"),
formatName.call("last")); (2)
}
String formatName(String raw) {
return Character.toUpperCase(raw.charAt(0))
+ raw.substring(1).toLowerCase();
}| 1 | Define a UDF that takes a single parameter and performs proper name capitalization |
| 2 | Apply the same UDF separately to the "first" and "last" name columns |
first last ------- -------- Jerry Cosin Juliana Walewski
In the example above, we called the UDF multiple times, each time with a different column name. A UDF can also be invoked with a numeric position or a full expression instead of a column name.
Above, we used Udf1 function, that takes only one expression (or column) as an input. Generally, UDFs can take
any number of expressions (columns). There are Udf1, Udf2, Udf3 and UdfN interfaces. The latter can take any
number of arguments and should be used to model UDFs with more than 3 inputs or a variable number of inputs:
DataFrame df = DataFrame.foldByRow("first", "last").of(
"Jerry", "Cosin",
null, "Walewski",
"Joan", null);
UdfN<Boolean> noNulls = exps -> and( (1)
Stream.of(exps)
.map(Exp::isNotNull)
.toArray(Condition[]::new)
);
DataFrame clean = df
.rows(noNulls.call("first", "last").castAsBool()) (2)
.select();| 1 | Build a UDF with dynamic number of input parameters packaged in the Exp[] |
| 2 | Call the UDF to create a row filter. Since the UDF return type is Exp<Boolean>,
we need to explicitly "cast" it to Condition expected by the RowSet, so we used castAsBool() |
first last ----- ----- Jerry Cosin
Performance hint: If the logic within a UDF requires converting a column to a specific data type,
and the column you are applying it to is known to be of that type already, you can speed up evaluation
by passing an expression of that type to the UDF. E.g. if a UDF calls castAsInt() on its argument,
udf.call($int("a")) is much faster than udf.call("a").
|
Using Relational Databases
Relational databases are arguably the most important type of data stores out there. Also they happen to map really well to DataFrames. DFLib provides advanced support for loading and saving DataFrames to RDBMS. It supports transactions, auto-generation of certain SQL statements, merging of data on top of the existing data ("create-or-update"), building custom SQL for selects and updates. It knows how to treat different DB "flavors" and does a number of other cool database-related things.
To start using all this, you need to import dflib-jdbc module:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-jdbc</artifactId>
</dependency>
<!-- Additionally, you need to import your JDBC driver -->
<dependency> ... </dependency>JdbcConnector
Once the imports are set up, you’d use Jdbc class to create an instance of JdbcConnector that will be used for
all DB operations. You may already have a preconfigured javax.sql.DataSource, so the simplest way to create a
connector is to pass that DataSource to Jdbc factory method:
JdbcConnector connector = Jdbc.connector(dataSource);Or you can specify the connection information directly:
JdbcConnector connector = Jdbc
.connector("jdbc:derby:target/derby/mydb;create=true")
// .driver("com.foo.MyDriver") (1)
// .userName("root")
// .password("secret") (2)
.build();| 1 | (Optional) Driver name. Some drivers are not packaged in a JDBC-compliant manner, and require an explicit declaration. |
| 2 | DB account username/password (not needed for our in-memory Derby example, but will definitely be required for a real database). |
TableLoader / TableSaver
Once you have the connector, you can start reading and persisting DataFrame data. A DataFrame can map directly to
a single table (or a view) from the database. If that’s the case, DFLib provides a set of rather straightforward
operations that do not require the user to write SQL (SQL is auto-generated by the framework):
DataFrame df = connector.tableLoader("person").load();id name salary -- ----------------- -------- 1 Jerry Cosin 70000.0 2 Juliana Walewski 85000.0 3 Joan O'Hara 101000.0
Table loader provides a way to customize the load operation. It allows to select specific columns, set the maximum number of rows to read, sample rows, and even specify fetch condition as another DataFrame. Some examples:
DataFrame condition = DataFrame
.byColumn("salary")
.of(Series.ofInt(70_000, 101_000));
DataFrame df = connector.tableLoader("person")
.cols("name", "salary")
.eq(condition)
.load();name salary ----------- -------- Jerry Cosin 70000.0 Joan O'Hara 101000.0
What it doesn’t require (unlike CSV loader) is explicit column types, as the proper value types are inferred from the database metadata.
Table saver allows to save DataFrame to a table. Column names in the DataFrame should match column names in the DB table:
DataFrame df = DataFrame.byArrayRow("id", "name", "salary")
.appender()
.append(1, "Jerry Cosin", 70_000)
.append(2, "Juliana Walewski", 85_000)
.append(3, "Joan O'Hara", 101_000)
.toDataFrame();
connector.tableSaver("person").save(df);In this scenario table saver executes insert for each DataFrame row. But what if there is already an existing data in the table? There are a few options the user has to overwrite or merge the data:
-
Append the data (that’s what we effectively did above).
-
Delete all existing data before doing the insert.
-
Merge the data by comparing DataFrame and DB table data on PK column(s) or an arbitrary set of columns. Insert missing rows, update the existing rows. If the table has more columns than there are columns in the DataFrame, the data in those extra columns is preserved.
Delete before insert example:
connector.tableSaver("person")
.deleteTableData()
.save(df);Merge by PK example (PK columns are detected from DB metadata) :
connector.tableSaver("person")
.mergeByPk()
.save(df);SqlLoader / SqlSaver
If your data has complex filtering conditions, spans more than one table or otherwise requires a customized
query, TableLoader can not be used. The alternative is to write your own SQL and execute it via SqlLoader:
DataFrame df = connector.sqlLoader("""
select "name", "city"
from "person" p
left join "address" a on (p."id" = a."person_id")
where "salary" > 80000
order by "name", "city"
""").load();name city ---------------- ------ Joan O'Hara Minsk Joan O'Hara Warsaw Juliana Walewski London
80000 value is hardcoded in the example above. We can make it a dynamic parameter, replacing it in the SQL with a
? sign and passing the value in the .load(..) method:
DataFrame df = connector.sqlLoader("""
select "name", "city"
from "person" p
left join "address" a on (p."id" = a."person_id")
where "salary" > ?
order by "name", "city"
""").load(80000);A few things to note here. The SQL String is written in a format of java.sql.PreparedStatement. So, ? placeholders
denote dynamic parameters. Parameters are positional (each ? position is matched with a value at that position in the
load(..) argument). Parameters can only be values, you can’t pass pieces of SQL as parameters. This is a
PreparedStatement behavior that prevents SQL injection attacks.
Similarly, to save data with custom SQL, you would use SqlSaver:
DataFrame df = DataFrame.byArrayRow("id", "name", "salary")
.appender()
.append(1, "Jerry Cosin", 70_000)
.append(2, "Juliana Walewski", 85_000)
.append(3, "Joan O'Hara", 101_000)
.toDataFrame();
connector.sqlSaver("""
insert into "person" values (?, ?, ?)
""").save(df);SQL parameters should match a "row" in the .save(..) argument. If the argument is a Series or an Object[],
it is treated as a single row of values, and will be bound to the prepared statement parameters by position. If the
argument is a DataFrame, the statement will be executed multiple times, once per each row.
DFLib code contains some JDBC-level
batching optimizations transparent to the user, that make the latter work faster, still the result you’d
observe would look as if you ran the SQL n times, where "n" is the height of the DataFrame.
CSV Format
CSV (comma-separated values) is a very common and rather simple format for working with raw data. *.csv files can be
manipulated programmatically or manually (via Excel/LibreOffice), loaded to / from databases, etc. DFLib supports
reading DataFrames from CSV and storing them to CSV. You need to add an extra dependency to your project to take
advantage of this functionality:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-csv</artifactId>
</dependency>Once you do that, Csv class is the entry point to all the .csv related operations as discussed below.
Reading CSV
The simplest way to create a DataFrame from a CSV file is this:
DataFrame df = Csv.load("src/test/resources/f1.csv"); (1)| 1 | The argument to the "load" method can be a filename, a file, or a Reader, so it can be loaded from a variety of sources. |
The result is a DataFrame that matches the CSV structure:
A B - -- 1 s1 4 s2
DFLib made a few assumptions about the data in f1.csv, namely that the first row represents
column names, that all columns are Strings, and that all of them need to be included. These assumptions are not
necessarily true with many data sets. So there is a longer form of this API that allows to configure column types,
skip rows and columns, or even sample the data without loading the entire CSV in memory. Some examples:
DataFrame df = Csv.loader() (1)
.offset(1) (2)
.header("x", "y") (3)
.intCol("x") (4)
.load("src/test/resources/f1.csv");| 1 | Instead of "load" method use "loader". |
| 2 | Skip the header row. |
| 3 | Provide our own header. |
| 4 | Convert the first column to int. |
x y - -- 1 s1 4 s2
| In theory, you don’t have to do most of these tweaks via CSV loader. You can load the raw data, and then use standard DataFrame transformations to shape the result. However, doing it via the loader allows to optimize both load speed and memory use, so it is usually preferable. |
The examples above showed how to read a CSV from a local file using a String file name. Instead of a String name, you can
also pass java.nio.file.Path or java.io.File objects. More generally, you can read a CSV from a URL or any other
source representable as ByteSource or ByteSources (see "Binary Data Sources" chapter).
Writing CSV
Writing to a CSV is equally easy:
Csv.save(df, "target/df.csv"); (1)| 1 | The argument to the "save" method can be a filename, a file, a Writer (or generally Appendable), so it can be stored to a variety of destinations. |
Just like with the loader, CSV saver provides its own set of options, if the defaults are not sufficient:
Csv.saver() (1)
.createMissingDirs() (2)
.format(CSVFormat.EXCEL) (3)
.save(df, "target/csv/df.csv");| 1 | Instead of "save" method use "saver" to be able to customize the process. |
| 2 | If intermediate directories for the output file are missing, create them. |
| 3 | Provide an alternative format (either from a collection of known formats, or user-specific). |
Excel Format
Excel format is very common in the business and finance world. DFLib supports reading DataFrames from and storing them to Excel. You need to add an extra dependency to your project to take advantage of this functionality:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-excel</artifactId>
</dependency>TODO…
Avro Format
Avro binary format is common in data engineering. Its main advantage is that .avro files are saved with
an embedded schema. So when they are read back, the fields are converted to the correct Java types. This is different
from CSV, as reading a .csv by default produces a DataFrame with all String columns. To work with the Avro format,
include the following dependency:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-avro</artifactId>
</dependency>Once you do that, Avro class is the entry point to all the operations. With it you can save DataFrames to .avro
files and load them back.
Avro Schema
In most cases you don’t need to know anything about Avro schemas. DFLib automatically generates a schema for a
DataFrame before it is saved. Alternatively you can create a custom Schema object based on
Avro specification and pass it to AvroSaver.
TODO…
Parquet Format
Parquet is a popular columnar binary data format. Like, .avro, .parquet files are saved with
an embedded schema. So when they are read back, the fields are converted to the correct Java types.
To work with the Parquet format, include the following dependency:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-parquet</artifactId>
</dependency>Once you do that, Parquet class is the entry point to all the operations. With it you can save DataFrames to .parquet
files and load them back.
TODO…
JSON Format
DFLib provides JSON load and save operations. To start, add the following dependency:
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-json</artifactId>
</dependency>From here, Json class is the entry point to both operations.
Reading JSON
JSON is used to model nested tree-like data structures, whereas DataFrame is a flat table. So to load JSON to a table,
some kind of "flattening" conversion is needed. DFLib JsonLoader uses
JSONPath query language to "navigate" the JSON tree and map parts of its
data to DataFrame columns. But first let’s look how JSON inputs are interpreted without an explicit mapping.
Default JSON Mapping
-
If JSON root is a list, each list element is converted into a row of the result
DataFrame. For each element:-
if it is a scalar, its value is placed in a special cell called
_val -
if it is an object, each object property is placed in a column matching this property name. The objects in the list do not all have to have the same properties. The resulting
DataFramecolumns will be a "union" of all properties encountered in the list.
String json = """ [ 5, { "a":1, "b":"S1" }, { "a":2, "b":"S2", "c":"S3" }, { "a":3, "c":"S4", "d":false } ]"""; DataFrame df = Json .loader() .load(json);_val a b c d ---- ---- ---- ---- ----- 5 null null null null null 1 S1 null null null 2 S2 S3 null null 3 null S4 false
Unlike CsvLoader, a String argument forJsonLoader.load(..)method is interpreted as JSON body, not a file name. These APIs will likely be better unified in the future versions. -
-
If JSON root is an object, then each of its properties is treated as a row. Property values are handled the same way as list elements in the previous example - scalars are placed in
_val, and property names are converted into columns:String json = """ { "p1" : 5, "p2" : { "a":1, "b":"S1" }, "p3" : { "a":2, "b":"S2", "c":"S3" }, "p4" : { "a":3, "c":"S4", "d":false } }"""; DataFrame df = Json .loader() .load(json);The same exact
DataFrameas in the first example is produced:_val a b c d ---- ---- ---- ---- ----- 5 null null null null null 1 S1 null null null 2 S2 S3 null null 3 null S4 false
-
If the cell values are not scalars, but are themselves JSON lists or objects, they are converted to Java
ListandMapinstances:Function<Object, String> labeler = o -> switch (o) { (1) case List l -> "list"; case Map m -> "map"; default -> "scalar"; }; String json = """ [ { "a": [1,2,3] }, { "a": {"b":4, "c":5} }, { "a": {"b":[6,7]} } ]"""; DataFrame df = Json .loader() .load(json) .cols("L1").merge($col("a").mapVal(labeler)) (2) .cols("L2").merge($col("a").mapVal(o -> switch (o) { (3) case List l -> labeler.apply(l.get(0)); case Map m -> labeler.apply(m.values().iterator().next()); default -> "scalar"; }));1 A function to help us analyze the result values 2 Checking the type of values in column a3 Checking the type of values in column acollectionsa L1 L2 ---------- ---- ------ [1,2,3] list scalar {b=4, c=5} map scalar {b=[6,7]} map list
JSON Mapping with JSONPath
JSONPath is a recently standardized query language to navigate through JSON
and select its elements. It can help greatly in parsing deeply-nested JSON structures and extracting only the relevant data.
JsonLoader accepts a single optional JSONPath expression.
The default implicit expression is $.* which means "select all children of the root node". All
the examples above behaved as if this expression was specified.
|
Some examples of using JSONPath:
-
Read the root JSON object as a single row
String json = """ { "a":1, "b":"S1" }"""; DataFrame df = Json .loader() .pathExpression("$") (1) .load(json);1 JSONPath of $selects the root nodea b - -- 1 S1
-
Read only a few specific properties of the root’s children
String json = """ [ 5, { "a":1, "b":"S1" }, { "a":2, "b":"S2", "c":"S3" }, { "a":3, "c":"S4", "d":false } ]"""; DataFrame df = Json .loader() .pathExpression("$..['a','b']") (1) .load(json);1 Selects properties aandba b - -- 1 S1 2 S2
-
Include objects with missing properties. Notice that the first and the last elements from the source JSON list in the previous example were excluded from the result. The first was a scalar that doesn’t have either
aorbproperty, and the last - an object witha, but without thebproperty. This is the intended default behavior of this JSONPath query, and it can be partially altered viaJsonLoader.nullsForMissingLeafs():String json = """ [ 5, { "a":1, "b":"S1" }, { "a":2, "b":"S2", "c":"S3" }, { "a":3, "c":"S4", "d":false } ]"""; DataFrame df = Json .loader() .pathExpression("$..['a','b']") .nullsForMissingLeafs() (1) .load(json);1 The object with no aorbproperty is included, but the scalar value is still excludeda b - ---- 1 S1 2 S2 3 null
-
Read data from a child node
String json = """ { "data" : [ { "a":1, "b":"S1" }, { "a":2, "b":"S2" }, { "a":3, "b":"S4" } ] }"""; DataFrame df = Json .loader() .pathExpression("$.data.*") (1) .nullsForMissingLeafs() .load(json);1 This JSONPath query finds the dataproperty of the root node and sets it as the root for theDataFramedata extractiona b - -- 1 S1 2 S2 3 S4
JSON Data Sources
Just like CSV, JSON data can be read from local files (java.nio.file.Path or java.io.File) as well as from
a ByteSource or ByteSources, such as URLs (see "Binary Data Sources" chapter).
Writing JSON
JsonSaver generates JSON from DataFrames in a "list-of-objects" format:
DataFrame df = DataFrame
.byArrayRow("name", "age")
.appender()
.append("Joe", 18)
.append("Andrus", 45)
.append("Joan", 32)
.toDataFrame();
String json = Json
.saver()
.saveToString(df); (1)| 1 | This form of "save" produces a JSON String |
[
{"name":"Joe","age":18},
{"name":"Andrus","age":45},
{"name":"Joan","age":32}
]
Similarly, you can save JSON to a file or to an Appendable.
Binary Data Sources
There are two interfaces that allow format-specific DFLib loaders to access streams of bytes and produce DataFrame
instances. Those are ByteSource, a single binary resource and ByteSources, a collection of such resources. Most
loaders accept ByteSource (and sometimes, ByteSources) as an argument to their load(..)
method. E.g. loaders for CSV, Avro, Parquet, JSON support both ByteSource and ByteSources, Excel loader supports
ByteSource, and JDBC loader supports neither (because JDBC doesn’t expose ResultSets as byte streams).
DFLib provides a growing number of out-of-the-box ByteSource implementations as described below. And you can
implement your own if needed.
ByteSources doesn’t have any interesting implementations as of DFlib 1.x, but in the future releases there will
be sources for ZIP archives, cloud folders, and such.
|
Byte Array ByteSource
The simplest ByteSource is a wrapper around a byte[]:
byte[] bytes = // ...
ByteSource src = ByteSource.of(bytes); (1)
DataFrame df = Csv
.loader()
.load(src); (2)| 1 | Create a ByteSource from a byte[] |
| 2 | To make a DataFrame, use an appropriate loader matching the format of the data stored in the byte[] |
URL ByteSource
Lots of data exists on the web that can be accessed via URLs. There is a ByteSource for that. Of course the URL
must be publicly accessible:
ByteSource src = ByteSource.ofUrl("https://example.org/my.csv");Also, the JVM can expose application resources as URLs, and the same API can be used to create a ByteSource:
ByteSource src = ByteSource.ofUrl(getClass().getResource("f1.csv"));HTTP ByteSource
While the ByteSource.ofUrl(..) example above works well for simple public URLs, DFLib provides a more advanced HTTP connector to
access web resources. It allows to send authorization (or any other) headers and also build URLs from parts incrementally:
ByteSource src = Http.of("https://example.org/")
.path("dir/my.csv")
.queryParam("ts", System.currentTimeMillis())
.header("Authorization", "Bearer abcdefghijklmnop")
.source();
Http connector is immutable. Each builder method above produces an altered copy of the original connector. This
means you can reuse a partially built connector to produce multiple resource-specific connectors.
|
Using JShell
Modern JDK installations come with jshell, a Read-Evaluate-Print Loop tool (aka REPL). DFLib can be used in
JShell environment for interactive data exploration and code prototyping. For the best experience, you may want to
configure a couple of things. Start jshell and execute the following commands:
// Set classpath.
// There's no automatic dependency management in jshell.
// You will need to include all DFLib jars and their
// dependencies explicitly
/env --class-path /path/to/dflib-1.2.0.jar:/path/to/dflib-csv-1.2.0.jar// Disable data truncation. You want your data to be visible.
/set mode mine normal -command
/set truncation mine 40000
/set feedback mine// Add needed imports
import org.dflib.*;
import org.dflib.csv.*;
import static org.dflib.Exp.*;// Set tabular printer
Environment.setPrinter(Printers.tabular());After this, you can start working with DataFrames and immediately check the output:
var df = Csv.load("../data/stuff.csv");JShell may print something like this
df ==> id name salary ---- ----------------- -------- 1 Jerry Cosin 70000.0 2 Juliana Walewski 85000.0 3 Joan O'Hara 101000.0 ... 997 Jenny Harris 65000.0 998 Matt Ostin 52000.0 999 Andrew Tsui 99000.0 1000 rows x 3 columns
Using Jupyter Notebook
While DFLib runs inside regular Java applications or jshell, it also works perfectly in Jupyter, which is a very
common "notebook" environment among data scientists and data engineers. In a notebook, you interact with your code via
a web browser in a rather visual way. It allows to run steps of a data transformation one-by-one and inspect the
data between the steps. Jupyter is often associated with Python / pandas, but it can also be used with Java / DFLib.
The code developed in a notebook can be later copied and pasted into your application. Java developers should consider using either Jupyter as a part of their data project workflow, and DFLib design (and its Jupyter integration features described here) makes it rather easy.
Java support for Jupyter is provided by jjava project that is also maintained by the DFLib community. Once you follow
the installation instructions and then
run Jupyter, you should end up with a browser window open with
Jupyter UI. Create a new notebook, and when asked to select a kernel, pick "Java". In the first cell enter something
like this:
%maven org.dflib:dflib-jupyter:1.2.0 (1)| 1 | Adding dflib-jupyter as a dependency also includes all other DFLib modules through its transitive dependencies.
Also, it will load base DFLib imports, and configure Jupyter environment for pretty display of DataFrames and Series. |
Click "Shift + Return" to execute the cell. If there are no errors, you can start using DFLib API in the following cells. E.g.:
DataFrame df = DataFrame.foldByColumn("a", "b", "c")
.ofInts(-1, 1, 2, 3, 4, 5, 6);
// the result of the last statement in a cell is printed just below it
dfDFLib development is literally "visual" in Jupyter, as in addition to tabular data, you can display graphical charts with contents of DataFrames:
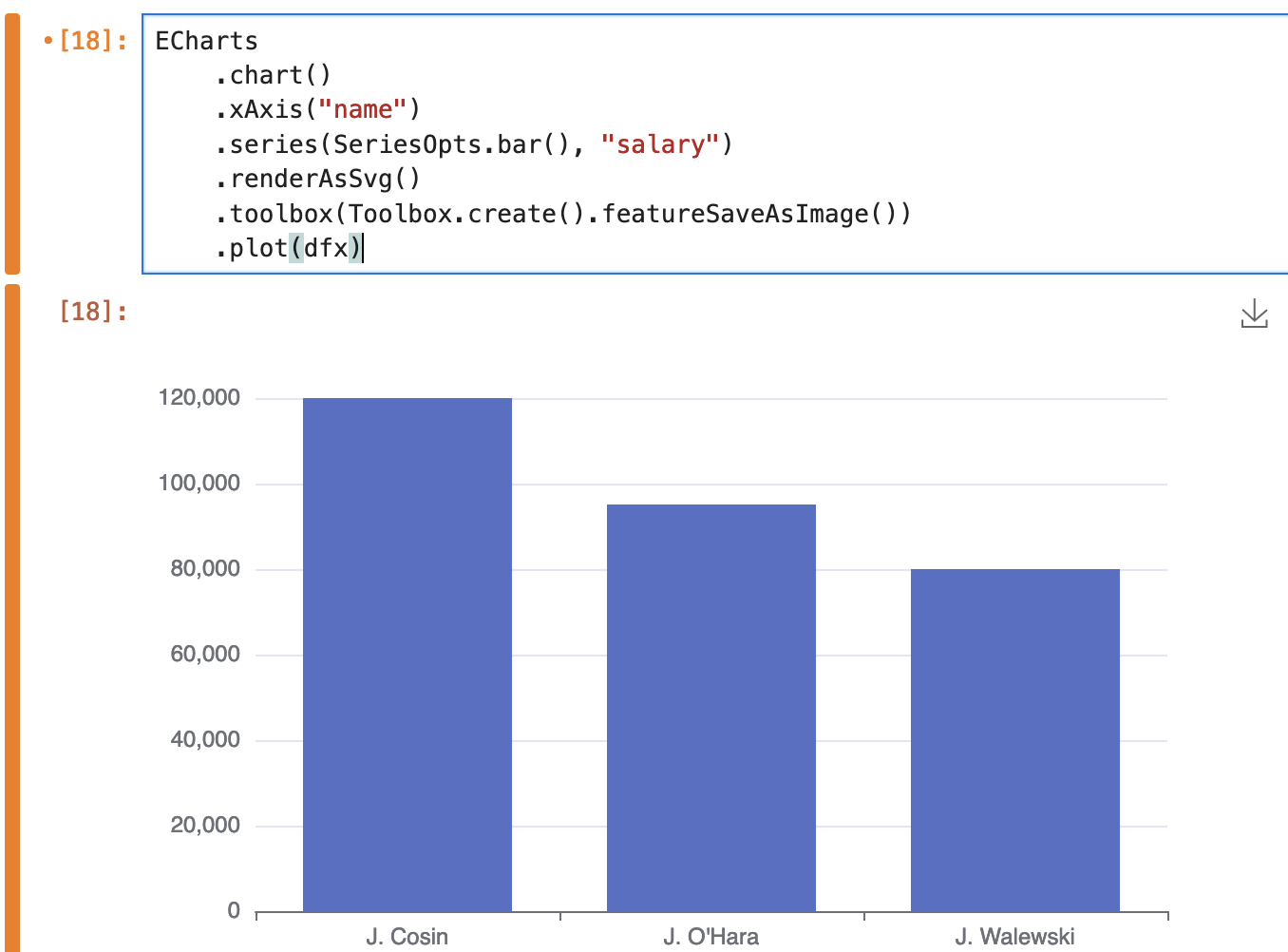
Change Display Parameters
To control truncation behavior, you can use static methods on DFLibJupyter:
DFLibJupyter.setMaxDisplayRows(10);
DFLibJupyter.setMaxDisplayColumnWidth(50);Charting with ECharts
DFLib provides a simple Java API to generate charts from DataFrames based on the Apache ECharts library. Charts are produced as pieces of HTML/JavaScript code and can be rendered either in Jupyter notebooks or served to the browser in a webapp.
The focus of this chapter is the DFLib API. We don’t dwell much on the underlying ECharts concepts, so you may need to read
their documentation to get explanations of things like multiple axes, grid, etc. The main difference of the DFLib
approach is that you don’t need to explicitly specify chart dataset or data sections. Instead, you’d define which
DataFrame columns should be used for chart series, axes, etc., and DFLib generates the data-related parts
from the provided DataFrame.
The ECharts JavaScript API contains a very large number of chart types and configuration options. DFLib
EChart class supports a growing, but incomplete subset of that API. If we are missing a feature that you need,
please open a task on GitHub, and we’ll do our best to integrate it.
|
To work with the ECharts API, you should include the following dependency (already included in the Jupyter environment):
<dependency>
<groupId>org.dflib</groupId>
<artifactId>dflib-echarts</artifactId>
</dependency>And then you can create a chart. E.g., here is a simple bar chart showing employee salaries:
DataFrame df = DataFrame.foldByRow("name", "salary").of(
"J. Cosin", 120000,
"J. Walewski", 80000,
"J. O'Hara", 95000)
.sort($col("salary").desc());
EChartHtml chart = ECharts
.chart()
.xAxis("name")
.series(SeriesOpts.ofBar(), "salary")
.plot(df);EChartHtml object contains pieces of HTML and JavaScript needed to render the following chart in the browser:

Running this code in Jupyter will render the chart above in the browser. So you don’t need to do anything
special to display it. When embedding charts in web applications, you’ll need to inspect EChartHtml.getContainer(),
EChartHtml.getExternalScript(), EChartHtml.getScript() methods and insert them in your HTML as you see fit.
Line Charts
TODO
Bar Charts
TODO
Scatter Charts
TODO
Pie Charts
TODO
Candlestick Charts
TODO
Unit Testing
TODO